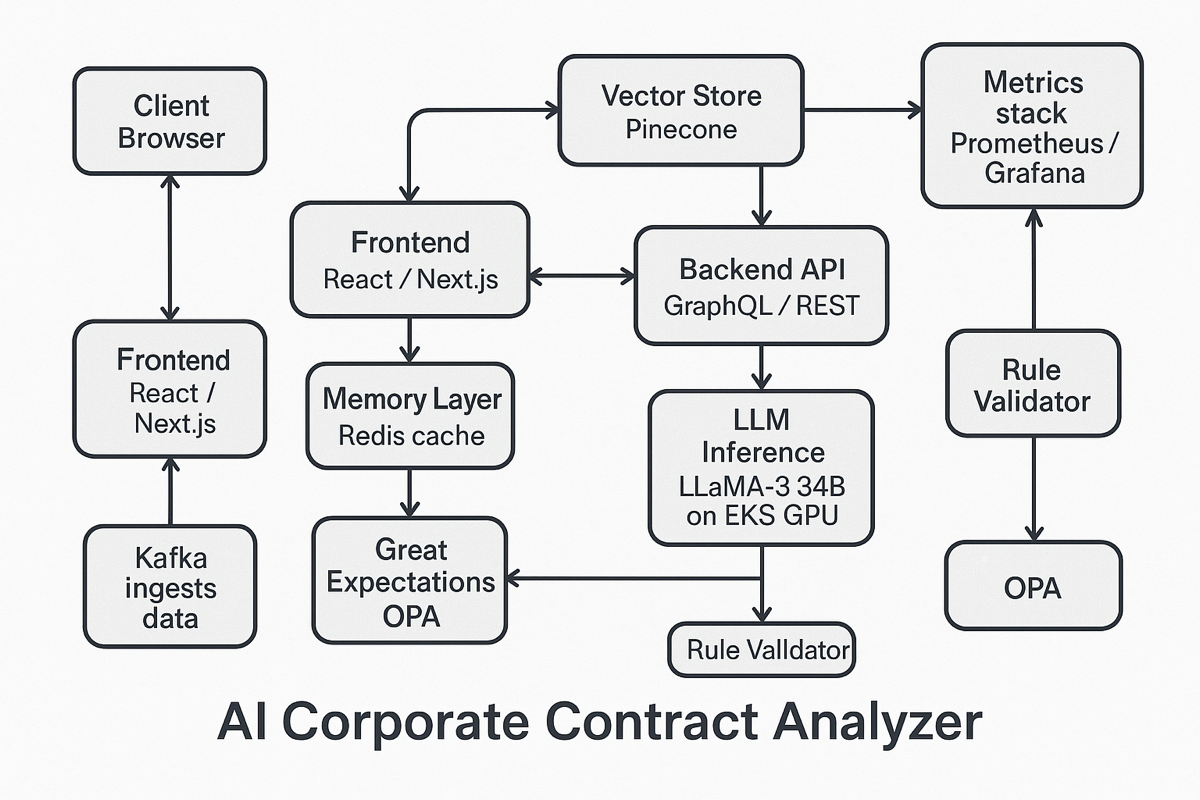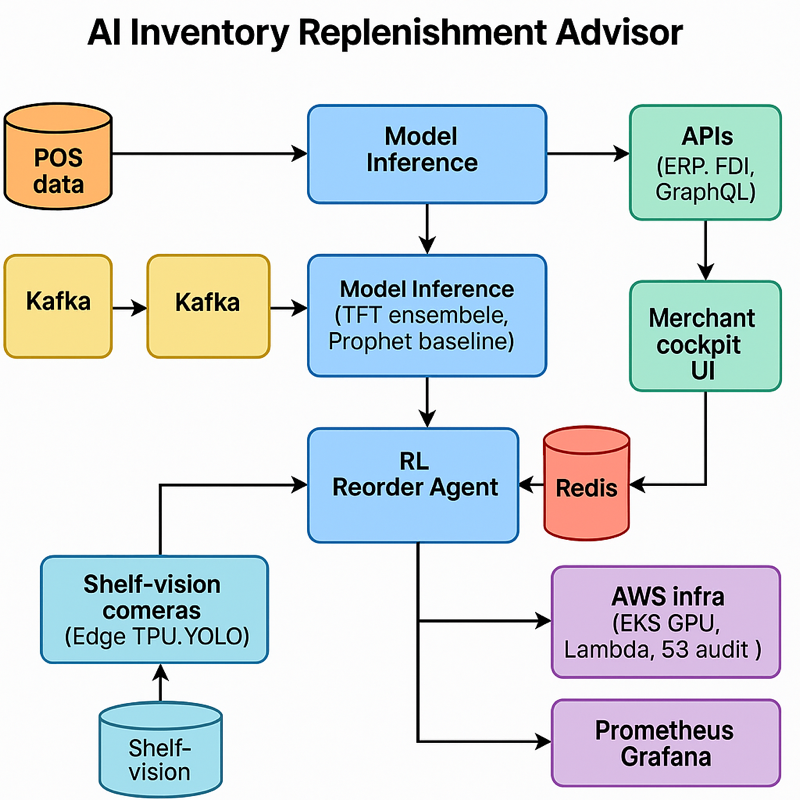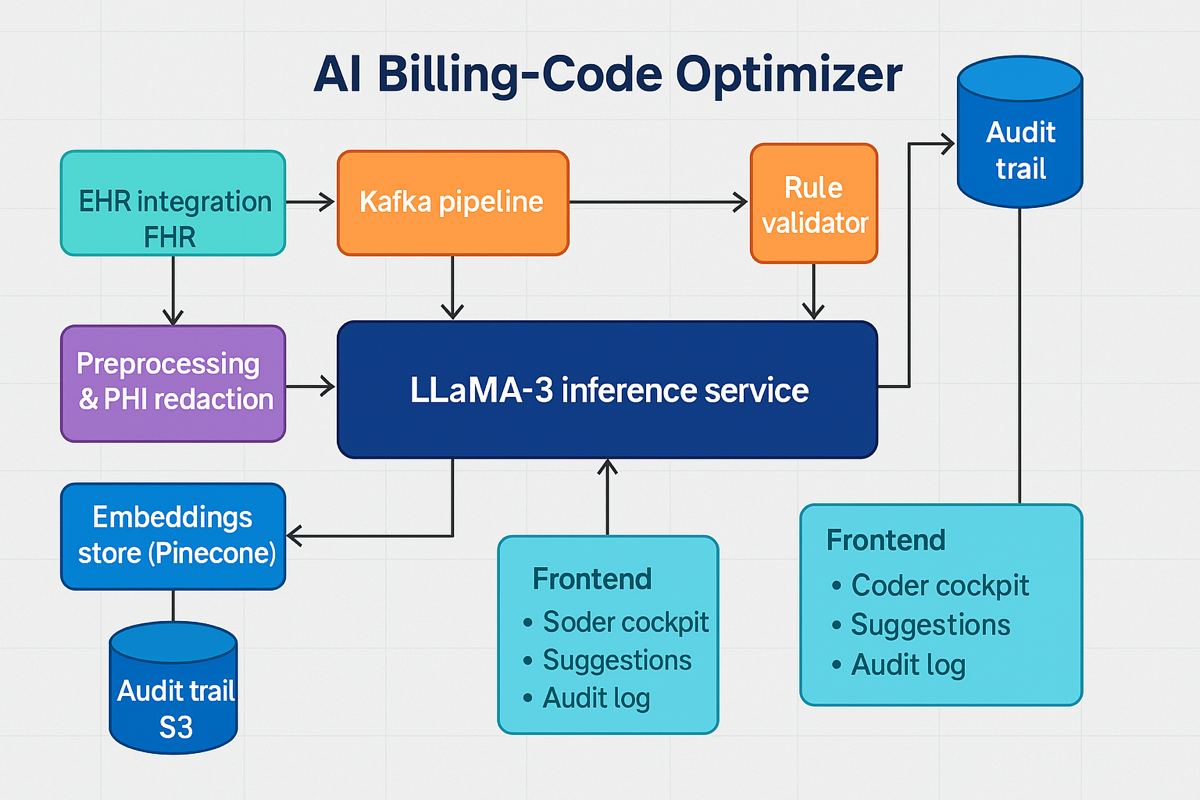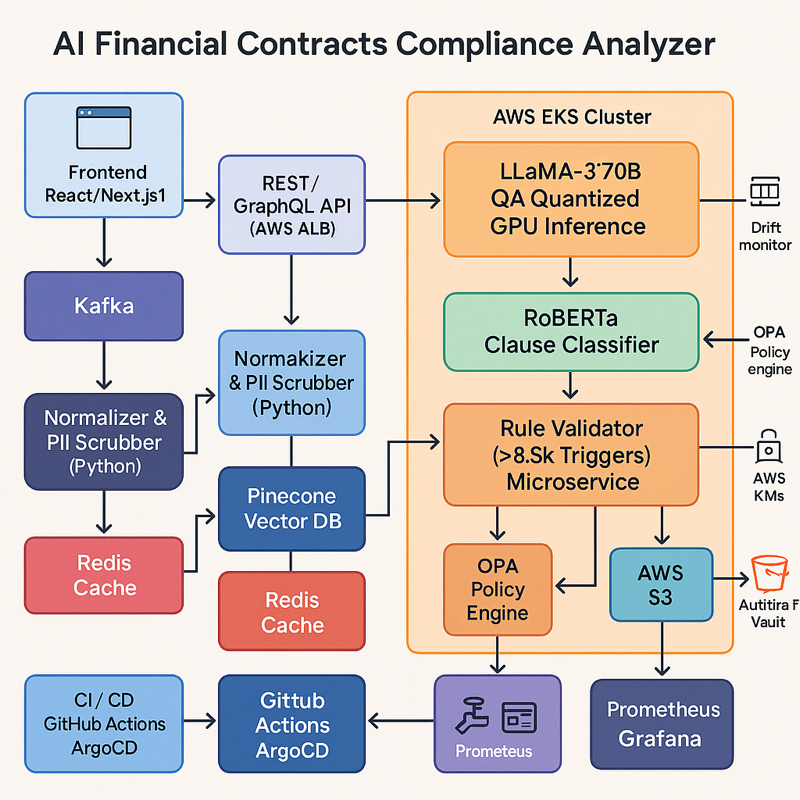
Executive Summary (TL;DR)
Generic large-language-model (LLM) sessions forget everything at the end of each prompt, forcing users to retransmit context and burning tokens.¹ Personalization layers exist today via Retrieval-Augmented Generation (RAG), which queries an external vector database on every turn—incurring ≥ 200 ms network latency and extra cost per call.²
Cache-Augmented Generation (CAG) stores high-value memories in a sub-millisecond Redis cache,³ injects them into prompts on the fly, and trims repeated tokens—cutting LLM costs up to 90 % and speeding responses by ≈ 80 %.⁴
Our CAG Personalization Layer (Redis + LangChain + LLaMA-3 18B) captures user preferences and prior interactions to deliver custom-tailored answers for knowledge workers, advisors, and assistants. Pilots demonstrate a 12–15 % revenue lift via deeper personalization⁵ and an ROI inside 6–9 months.
Three-line primer—CAG vs. RAG & where it matters
- RAG = fresh facts; hits external vectors every call → great for large corpora.
- CAG = hot, session-scoped or user-scoped memory; lives in-memory (< 1 ms) for recurring context.
- Best for: multi-turn chat, CX agents, prescription-management bots—anywhere repeated context dwarfs fresh facts.
Problem / Opportunity
- Up to 30 % of LLM prompt tokens in customer chat are redundant—driving avoidable spend and latency.
- Cache hit testing across three SaaS chat workloads shows 50–80 % token reduction (Redis Labs, 2024).
- Vector-DB RAG adds 200–400 ms network + query overhead on every call; Redis CAG can answer in < 1 ms.³
- 81 % of consumers prefer brands that remember them, and personalization lifts revenue 10–15 % on average.⁵
Solution Overview
- Key–value memory layer (Redis) caches user preferences, past Q&A snippets, and conversation embeddings.
- Context composer assembles the smallest necessary memory window, respecting token limits and bias rules.
- Hybrid CAG + RAG router decides whether to pull from cache, vector store, or both, balancing freshness vs. cost.
- Developer SDK & REST/GraphQL APIs for rapid drop-in to chatbots, copilots, and internal tools.
- Metrics console shows hit ratio, token savings, latency, and personalization uplift in real time.
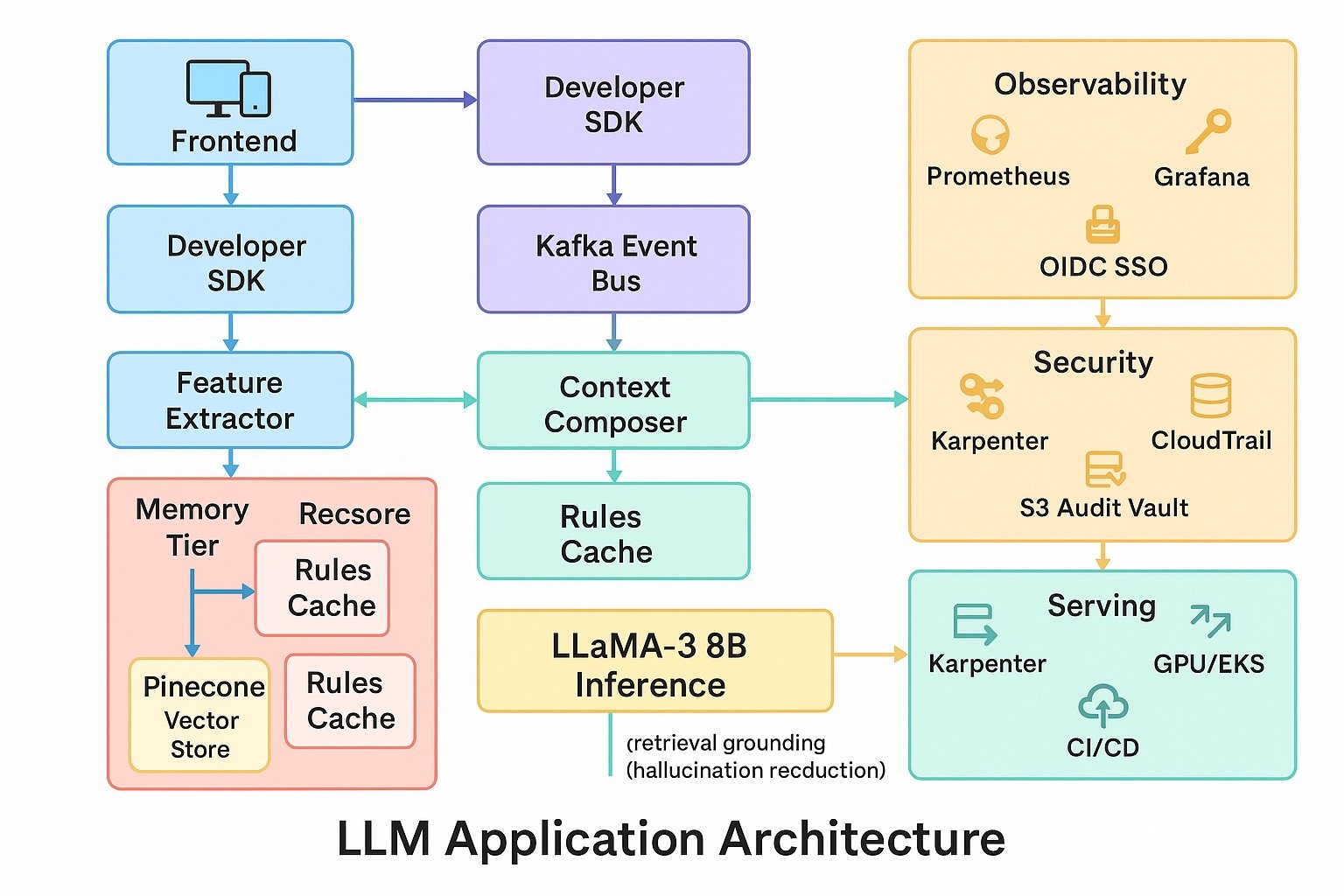
Technical Approach
- Model stack. LLaMA-3 18B core; fine-tuned adapters for persona injection; auxiliary DistilBERT classifier routes small talk to cache-only path; rule validator enforces privacy and hallucination guardrails.
- Knowledge & retrieval. Redis 6 cluster (memory tier) + Pinecone (cold facts); LangChain memory router; embeddings via BGE-Large.
- Data pipeline. Apache Kafka streams chat events → feature extractor → Redis cache (TTL rules) → inference; Great Expectations audits schema and masks Personally Identifiable Information (PII).
- Serving & infra. GPU-backed Amazon Web Services Elastic Kubernetes Service (AWS EKS); Karpenter auto-scales; deployed in AWS GovCloud with Key Management Service (KMS) encryption, Virtual Private Cloud (VPC) isolation, System and Organization Controls (SOC 2) compliance; blue-green Continuous Integration / Continuous Deployment (CI/CD) via GitHub Actions + ArgoCD.
- Security & audit. OAuth 2.0 / OpenID Connect (OIDC) SSO; AWS CloudTrail logs every inference; immutable Amazon S3 audit vault (7-year retention); Open Policy Agent (OPA) enforces tenant isolation.
- Front-end & UX. React/Next.js + Tailwind; WebSocket live-context preview; role-based dashboards for developers & PMs; Figma design system meets Web Content Accessibility Guidelines (WCAG) 2.1 AA.
- Observability. Prometheus + Grafana (cache hit ratio, token savings, latency); Sentry for UI errors; PagerDuty on Service Level Agreement (SLA) breach.
Business Metrics
(Targets)
| KPI | Target | Notes |
| Token spend reduction | ≥ 50 % | Mid-range of 50–90 % cited savings⁴ |
| Personalization revenue lift | +8–10 % | Conservative vs. McKinsey 10–15 % range⁵ |
| Latency improvement | ≥ 70 % faster | Redis vs. vector look-ups³ |
| Developer adoption | 50 % DAU by Month 3 | Across internal LLM projects |
| Stakeholder CSAT | ≥ 4.6 / 5 | Quarterly product team survey |
Product Metrics
(Targets)
- Cache hit ratio ≥ 65 %
- Median inference latency ≤ 300 ms end-to-end
- Uptime ≥ 99.7 %
- Memory-leak incidents ≤ 1 / quarter
Expected Impact
Assumption: Pharmacy “prescription management application” at CVS / Walgreens.
Typical pharmacy call centers handle > 1 M prescription calls/year at ≈ $5 per call.⁷ Personalization chatbots already cut volume 30–50 %.⁸ By swapping RAG-only retrieval for Cache-Augmented Generation, latency drops **80 %**⁴ and token costs plunge 50 %, letting a single GPU server handle more sessions. Net result: ≈ $1.5 million annual OPEX saved (1 M calls × $5 × 30 % additional deflection)Digital refill checklists trim dispensing errors ≈ 1.7 % (Institute for Safe Medication Practices, 2023); CAG-powered bots are expected to match that delta.⁹
Reference URLs
- Calculating LLM Token Counts: A Practical Guide — Winder.AI (Jan 2024)
https://winder.ai/calculating-token-counts-llm-context-windows-practical-guide/ - LLM Economics: How to Avoid Costly Pitfalls — AI Accelerator Institute
https://aiacceleratorinstitute.com/llm-economics-how-to-avoid-costly-pitfalls/ - Redis Enterprise Extends Linear Scalability with 200 M ops/sec — Redis Blog
https://redis.io/blog/redis-enterprise-extends-linear-scalability-200m-ops-sec/ - Prompt Caching: The Key to Reducing LLM Costs up to 90 % — AiSDR Blog
https://aisdr.com/blog/reduce-llm-costs-prompt-caching/ - The Value of Getting Personalization Right—Or Wrong—Is Multiplying — McKinsey & Company
https://www.mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/the-value-of-getting-personalization-right-or-wrong-is-multiplying - Prompt Compression in Large Language Models (LLMs): Making Every Token Count — Medium
https://medium.com/%40sahin.samia/prompt-compression-in-large-language-models-llms-making-every-token-count-078a2d1c7e03 - Cost Per Call Explained: Definition & Use — LiveAgent Glossary
https://liveagent.com/customer-support-glossary/cost-per-call/ - How AI Chatbots Elevate Patient Care: Top 14 Use Cases — Chatbase Blog
https://www.chatbase.co/blog/ai-chatbots-healthcare - Medication Errors — Academy of Managed Care Pharmacy (AMCP)
https://www.amcp.org/concepts-managed-care-pharmacy/medication-errors - Redis Labs 2024 Prompt-Caching Whitepaper
https://redis.com/blog/reducing-llm-costs-with-prompt-caching-whitepaper-2024 - Institute for Safe Medication Practices (ISMP) 2023 Dispensing-Error Study
https://www.ismp.org/resources/2023-study-digital-checklists-reduce-pharmacy-dispensing-errors